 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Should I Cite? A RAG Benchmark for Academic Citation Prediction
Jan 21, 2026With the rapid growth of Web-based academic publications, more and more papers are being published annually, making it increasingly difficult to find relevant prior work. Citation prediction aims to automatically suggest appropriate references, helping scholars navigate the expanding scientific literature. Here we present \textbf{CiteRAG}, the first comprehensive retrieval-augmented generation (RAG)-integrated benchmark for evaluating large language models on academic citation prediction, featuring a multi-level retrieval strategy, specialized retrievers, and generators. Our benchmark makes four core contributions: (1) We establish two instances of the citation prediction task with different granularity. Task 1 focuses on coarse-grained list-specific citation prediction, while Task 2 targets fine-grained position-specific citation prediction. To enhance these two tasks, we build a dataset containing 7,267 instances for Task 1 and 8,541 instances for Task 2, enabling comprehensive evaluation of both retrieval and generation. (2) We construct a three-level large-scale corpus with 554k papers spanning many major subfields, using an incremental pipeline. (3) We propose a multi-level hybrid RAG approach for citation prediction, fine-tuning embedding models with contrastive learning to capture complex citation relationships, paired with specialized generation models. (4) We conduct extensive experiments across state-of-the-art language models, including closed-source APIs, open-source models, and our fine-tuned generators, demonstrating the effectiveness of our framework. Our open-source toolkit enables reproducible evaluation and focuses on academic literature, providing the first comprehensive evaluation framework for citation prediction and serving as a methodological template for other scientific domains. Our source code and data are released at https://github.com/LQgdwind/CiteRAG.
Learning with Preserving for Continual Multitask Learning
Nov 11, 2025Artificial intelligence systems in critical fields like autonomous driving and medical imaging analysis often continually learn new tasks using a shared stream of input data. For instance, after learning to detect traffic signs, a model may later need to learn to classify traffic lights or different types of vehicles using the same camera feed. This scenario introduces a challenging setting we term Continual Multitask Learning (CMTL), where a model sequentially learns new tasks on an underlying data distribution without forgetting previously learned abilities. Existing continual learning methods often fail in this setting because they learn fragmented, task-specific features that interfere with one another. To address this, we introduce Learning with Preserving (LwP), a novel framework that shifts the focus from preserving task outputs to maintaining the geometric structure of the shared representation space. The core of LwP is a Dynamically Weighted Distance Preservation (DWDP) loss that prevents representation drift by regularizing the pairwise distances between latent data representations. This mechanism of preserving the underlying geometric structure allows the model to retain implicit knowledge and support diverse tasks without requiring a replay buffer, making it suitable for privacy-conscious applications. Extensive evaluations on time-series and image benchmarks show that LwP not only mitigates catastrophic forgetting but also consistently outperforms state-of-the-art baselines in CMTL tasks. Notably, our method shows superior robustness to distribution shifts and is the only approach to surpass the strong single-task learning baseline, underscoring its effectiveness for real-world dynamic environments.
LogicPuzzleRL: Cultivating Robust Mathematical Reasoning in LLMs via Reinforcement Learning
Jun 05, 2025Large language models (LLMs) excel at many supervised tasks but often struggle with structured reasoning in unfamiliar settings. This discrepancy suggests that standard fine-tuning pipelines may instill narrow, domain-specific heuristics rather than fostering general-purpose thinking strategies. In this work, we propose a "play to learn" framework that fine-tunes LLMs through reinforcement learning on a suite of seven custom logic puzzles, each designed to cultivate distinct reasoning skills such as constraint propagation, spatial consistency, and symbolic deduction. Using a reinforcement learning setup with verifiable rewards, models receive binary feedback based on puzzle correctness, encouraging iterative, hypothesis-driven problem solving. We demonstrate that this training approach significantly improves out-of-distribution performance on a range of mathematical benchmarks, especially for mid-difficulty problems that require multi-step reasoning. Analyses across problem categories and difficulty levels reveal that puzzle training promotes transferable reasoning routines, strengthening algebraic manipulation, geometric inference, and combinatorial logic, while offering limited gains on rote or highly specialized tasks. These findings show that reinforcement learning over logic puzzles reshapes the internal reasoning of LLMs, enabling more robust and compositional generalization without relying on task-specific symbolic tools.
LogiDebrief: A Signal-Temporal Logic based Automated Debriefing Approach with Large Language Models Integration
May 06, 2025Emergency response services are critical to public safety, with 9-1-1 call-takers playing a key role in ensuring timely and effective emergency operations. To ensure call-taking performance consistency, quality assurance is implemented to evaluate and refine call-takers' skillsets. However, traditional human-led evaluations struggle with high call volumes, leading to low coverage and delayed assessments. We introduce LogiDebrief, an AI-driven framework that automates traditional 9-1-1 call debriefing by integrating Signal-Temporal Logic (STL) with Large Language Models (LLMs) for fully-covered rigorous performance evaluation. LogiDebrief formalizes call-taking requirements as logical specifications, enabling systematic assessment of 9-1-1 calls against procedural guidelines. It employs a three-step verification process: (1) contextual understanding to identify responder types, incident classifications, and critical conditions; (2) STL-based runtime checking with LLM integration to ensure compliance; and (3) automated aggregation of results into quality assurance reports. Beyond its technical contributions, LogiDebrief has demonstrated real-world impact. Successfully deployed at Metro Nashville Department of Emergency Communications, it has assisted in debriefing 1,701 real-world calls, saving 311.85 hours of active engagement. Empirical evaluation with real-world data confirms its accuracy, while a case study and extensive user study highlight its effectiveness in enhancing call-taking performance.
Combining LLMs with Logic-Based Framework to Explain MCTS
May 01, 2025

In response to the lack of trust in Artificial Intelligence (AI) for sequential planning, we design a Computational Tree Logic-guided large language model (LLM)-based natural language explanation framework designed for the Monte Carlo Tree Search (MCTS) algorithm. MCTS is often considered challenging to interpret due to the complexity of its search trees, but our framework is flexible enough to handle a wide range of free-form post-hoc queries and knowledge-based inquiries centered around MCTS and the Markov Decision Process (MDP) of the application domain. By transforming user queries into logic and variable statements, our framework ensures that the evidence obtained from the search tree remains factually consistent with the underlying environmental dynamics and any constraints in the actual stochastic control process. We evaluate the framework rigorously through quantitative assessments, where it demonstrates strong performance in terms of accuracy and factual consistency.
Sim911: Towards Effective and Equitable 9-1-1 Dispatcher Training with an LLM-Enabled Simulation
Dec 24, 2024Emergency response services are vital for enhancing public safety by safeguarding the environment, property, and human lives. As frontline members of these services, 9-1-1 dispatchers have a direct impact on response times and the overall effectiveness of emergency operations. However, traditional dispatcher training methods, which rely on role-playing by experienced personnel, are labor-intensive, time-consuming, and often neglect the specific needs of underserved communities. To address these challenges, we introduce Sim911, the first training simulation for 9-1-1 dispatchers powered by Large Language Models (LLMs). Sim911 enhances training through three key technical innovations: (1) knowledge construction, which utilizes archived 9-1-1 call data to generate simulations that closely mirror real-world scenarios; (2) context-aware controlled generation, which employs dynamic prompts and vector bases to ensure that LLM behavior aligns with training objectives; and (3) validation with looped correction, which filters out low-quality responses and refines the system performance.
EVQAScore: Efficient Video Question Answering Data Evaluation
Nov 11, 2024



Video question-answering (QA) is a core task in video understanding. Evaluating the quality of video QA and video caption data quality for training video large language models (VideoLLMs) is an essential challenge. Although various methods have been proposed for assessing video caption quality, there remains a lack of dedicated evaluation methods for Video QA. To address this gap, we introduce EVQAScore, a reference-free method that leverages keyword extraction to assess both video caption and video QA data quality. Additionally, we incorporate frame sampling and rescaling techniques to enhance the efficiency and robustness of our evaluation, this enables our score to evaluate the quality of extremely long videos. Our approach achieves state-of-the-art (SOTA) performance (32.8 for Kendall correlation and 42.3 for Spearman correlation, 4.7 and 5.9 higher than the previous method PAC-S++) on the VATEX-EVAL benchmark for video caption evaluation. Furthermore, by using EVQAScore for data selection, we achieved SOTA results with only 12.5\% of the original data volume, outperforming the previous SOTA method PAC-S and 100\% of data.
Auto311: A Confidence-guided Automated System for Non-emergency Call
Dec 19, 2023



Emergency and non-emergency response systems are essential services provided by local governments and critical to protecting lives, the environment, and property. The effective handling of (non-)emergency calls is critical for public safety and well-being. By reducing the burden through non-emergency callers, residents in critical need of assistance through 911 will receive a fast and effective response. Collaborating with the Department of Emergency Communications (DEC) in Nashville, we analyzed 11,796 non-emergency call recordings and developed Auto311, the first automated system to handle 311 non-emergency calls, which (1) effectively and dynamically predicts ongoing non-emergency incident types to generate tailored case reports during the call; (2) itemizes essential information from dialogue contexts to complete the generated reports; and (3) strategically structures system-caller dialogues with optimized confidence. We used real-world data to evaluate the system's effectiveness and deployability. The experimental results indicate that the system effectively predicts incident type with an average F-1 score of 92.54%. Moreover, the system successfully itemizes critical information from relevant contexts to complete reports, evincing a 0.93 average consistency score compared to the ground truth. Additionally, emulations demonstrate that the system effectively decreases conversation turns as the utterance size gets more extensive and categorizes the ongoing call with 94.49% mean accuracy.
CitySpec with Shield: A Secure Intelligent Assistant for Requirement Formalization
Feb 19, 2023



An increasing number of monitoring systems have been developed in smart cities to ensure that the real-time operations of a city satisfy safety and performance requirements. However, many existing city requirements are written in English with missing, inaccurate, or ambiguous information. There is a high demand for assisting city policymakers in converting human-specified requirements to machine-understandable formal specifications for monitoring systems. To tackle this limitation, we build CitySpec, the first intelligent assistant system for requirement specification in smart cities. To create CitySpec, we first collect over 1,500 real-world city requirements across different domains (e.g., transportation and energy) from over 100 cities and extract city-specific knowledge to generate a dataset of city vocabulary with 3,061 words. We also build a translation model and enhance it through requirement synthesis and develop a novel online learning framework with shielded validation. The evaluation results on real-world city requirements show that CitySpec increases the sentence-level accuracy of requirement specification from 59.02% to 86.64%, and has strong adaptability to a new city and a new domain (e.g., the F1 score for requirements in Seattle increases from 77.6% to 93.75% with online learning). After the enhancement from the shield function, CitySpec is now immune to most known textual adversarial inputs (e.g., the attack success rate of DeepWordBug after the shield function is reduced to 0% from 82.73%). We test the CitySpec with 18 participants from different domains. CitySpec shows its strong usability and adaptability to different domains, and also its robustness to malicious inputs.
Bil-DOS: A Bi-lingual Dialogue Ordering System
Oct 11, 2022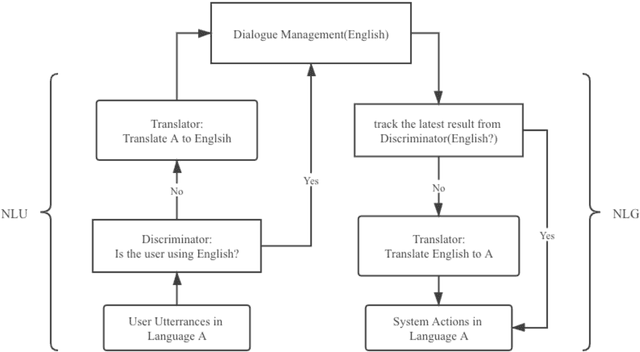
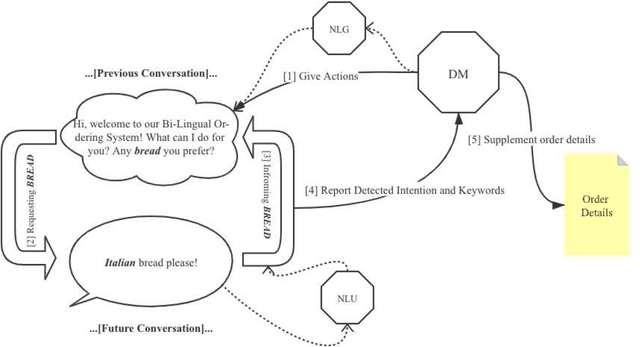

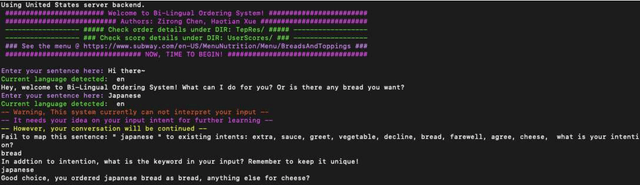
Due to the unfamiliarity to particular words(or proper nouns) for ingredients, non-native English speakers can be extremely confused about the ordering process in restaurants like Subway. Thus, We developed a dialogue system, which supports Chinese(Mandarin)1 and English2 at the same time. In other words, users can switch arbitrarily between Chinese(Mandarin) and English as the conversation is being conducted. This system is specifically designed for Subway ordering3. In BilDOS, we designed a Discriminator module to tell the language is being used in inputted user utterance, a Translator module to translate used language into English if it is not English, and a Dialogue Manager module to detect the intention within inputted user utterances, handle outlier inputs by throwing clarification requests, map detected Intention and detailed Keyword4 into a particular intention class, locate the current ordering process, continue to give queries to finish the order, conclude the order details once the order is completed, activate the evaluation process when the conversation is done.